
وبلاگ
برترین تجهیزات ذخیرهسازی داده برای توسعهدهندگان

در عصری که هر خط کد، هر درخواست API، هر تغییر در دیتابیس و هر آپدیت اپلیکیشن، دادهای جدید را تولید میکند، انتخاب تجهیزات ذخیرهسازی (Data Storage) مناسب نه تنها یک انتخاب فنی، بلکه یک استراتژی بقا برای هر توسعهدهندهای است که به کیفیت، سرعت و پایداری اهمیت میدهد. امروزه، دادهها نه تنها حجم بیشتری دارند، بلکه سرعت تولید، انواع مختلف و پیچیدگیهای ساختاری آنها نیز به شدت افزایش یافته است. توسعهدهندگانی که از سیستمهای قدیمی یا نامناسب استفاده میکنند، با تأخیرهای غیرقابل تحمل، خطاهای دادهای و هزینههای ناشناخته مواجه میشوند. این مقاله، نه تنها به معرفی بهترین ابزارها میپردازد، بلکه ریشههای فنی، مزایای عملیاتی و تجربیات واقعی توسعهدهندگان را در انتخاب این تجهیزات بررسی میکند. هدف ما، کمک به شما در ساخت زیرساختی استوار، مقیاسپذیر و آیندهنگر است — نه فقط برای امروز، بلکه برای سالهای آینده. این راهنمای جامع، بدون تبلیغات بیاساس و با تمرکز بر عملکرد واقعی، شما را از مفاهیم پایه تا انتخابهای پیشرفته همراهی میکند. در پایان به کمک irantech، نه تنها میدانید چه چیزی را بخرید، بلکه میفهمید چرا باید آن را بخرید.
چرا ذخیرهسازی داده برای توسعهدهندگان مهم است؟
ذخیرهسازی داده (Data Storage) تنها یک بخش از زیرساخت فنی نیست؛ بلکه ستون فقرات هر سیستم نرمافزاری مدرن است. از یک برنامهی موبایل ساده تا یک پلتفرم ابری جهانی — همه به دادههایی نیاز دارند که به درستی ذخیره، بازیابی، امنیت و بهروزرسانی شوند. توسعهدهندگان امروز نه تنها با حجم دادههای نجومی (Big Data) روبرو هستند، بلکه باید با تأخیرهای میکروثانیهای (microsecond latency) و سرعت دسترسی بالا (high IOPS) کار کنند. یک دیسک سخت (HDD) قدیمی ممکن است برای ذخیره فایلهای پشتیبان مناسب باشد، اما برای یک سرور دیتابیس NoSQL در محیط تولید، کاملاً ناکارآمد است. همچنین، انتخاب بین **SSD**، **NVMe**، **SAN**، **NAS**، یا حتی **object storage**، نه تنها بر عملکرد، بلکه بر هزینه، قابلیت اطمینان و حتی تجربه توسعهدهنده تأثیر مستقیم دارد. بسیاری از مشکلات عملیاتی — از کندی در تستهای یکپارچه (CI/CD) تا خطاهای دادهای در تولید — ریشه در انتخاب نادرست تجهیزات ذخیرهسازی دارند. این مقاله، شما را از مفاهیم پایه تا انتخابهای پیشرفته، همراهی میکند تا بتوانید تجهیزاتی را انتخاب کنید که نه تنها با پروژههای فعلی شما هماهنگ باشند، بلکه برای رشد آینده نیز مقیاسپذیر باشند.
انواع تجهیزات ذخیرهسازی داده از HDD تا Object Storage
1. HDD/ هنوز هم جایی دارد؟

هارد دیسکهای مغناطیسی (Hard Disk Drives) هنوز در برخی سناریوها جایگاه خود را حفظ کردهاند. این تجهیزات، بهویژه در محیطهایی که حجم داده بسیار بالا است اما نیاز به سرعت بالا وجود ندارد — مانند ذخیرهسازی فایلهای پشتیبان، لگهای قدیمی، یا آرشیو دادههای غیرفعال — همچنان انتخابی اقتصادی هستند. با قیمتی حدود ۲۰ دلار برای هر ترابایت، HDDها بهترین نسبت هزینه به ظرفیت را ارائه میدهند. اما این مزیت، با معیوبهایی جبران میشود: سرعت دسترسی بسیار پایین (میانگین ۵۰–۱۲۰ IOPS)، حساسیت به لرزش و ضربه، و مصرف انرژی بالاتر. برای توسعهدهندگانی که در محیطهای تست یا توسعه از ماشینهای محلی استفاده میکنند، استفاده از HDD برای دیتابیسهای فعال — مانند PostgreSQL یا MongoDB — تجربهای ناپذیرفتنی خواهد بود. اینها بهترین گزینه برای **archival storage** هستند، نه برای **high-performance workloads**.
2. SSD/ انقلاب در سرعت دسترسی

در سالهای اخیر، SSD (Solid State Drive) به استاندارد طلایی تبدیل شده است. با استفاده از حافظهی فلش (Flash Memory) و بدون قطعات متحرک، SSDها سرعت دسترسی را تا ۱۰۰ برابر نسبت به HDDها افزایش دادهاند. این تغییر، تجربه توسعهدهندگان را به طور بنیادی تغییر داد: اجرای تستهای واحد (unit tests)، اجرای دیتابیس محلی، و حتی کامپایل کردن کدهای بزرگ — همه در ثانیهها انجام میشوند. SSDها همچنین مصرف برق کمتری دارند، سر و صدایی ندارند، و در برابر ضربه مقاومترند. برای هر توسعهدهندهای که از لپتاپ استفاده میکند، یک SSD ۵۱۲GB یا ۱TB نه تنها یک ارتقا، بلکه یک ضرورت است. حتی در سرورهای کوچک، استفاده از SSD به جای HDD، زمان پاسخگویی (response time) را از چند ثانیه به چند میلیثانیه کاهش میدهد.
3. NVMe/ قله سرعت در ذخیرهسازی محلی

اگر SSD معمولی انقلابی بود، NVMe (Non-Volatile Memory Express) یک انفجار است. این پروتکل جدید، مستقیماً از طریق رابط PCIe (Peripheral Component Interconnect Express) با CPU ارتباط برقرار میکند — نه از طریق SATA که محدودیتهای فیزیکی خود را دارد. نتیجه؟ سرعتهای خواندن/نوشتن بالغ بر ۷,۰۰۰ MB/s و IOPS بیش از ۱ میلیون. این تکنولوژی، از دستهی **enterprise-grade SSDs** مانند Samsung 990 Pro یا Western Digital Black SN850X بهره میبرد. برای توسعهدهندگانی که با دیتابیسهای حجیم کار میکنند — مانند Elasticsearch، Redis، یا حتی PostgreSQL با حجم دادههای بالا — NVMe نه تنها یک انتخاب بهینه، بلکه یک ضرورت عملیاتی است. حتی در محیطهای توسعه محلی، استفاده از یک NVMe SSD باعث میشود که اجرای Docker Compose، ساخت دیتابیسهای تستی، و اجرای تستهای انتگرالی (integration tests) در کمتر از ۳۰ ثانیه انجام شود — نه چند دقیقه. این تفاوت، در طول یک روز کاری، چندین ساعت زمان را صرفهجویی میکند.
4. SAN و NAS/ ذخیرهسازی شبکهای برای تیمها

برای تیمهای توسعهدهنده که در محیطهای مشترک کار میکنند، ذخیرهسازی محلی کافی نیست. اینجا است که **SAN** (Storage Area Network) و **NAS** (Network Attached Storage) وارد میشوند. NAS سادهتر است: یک دستگاه متصل به شبکه است که از طریق پروتکلهایی مانند SMB یا NFS به اشتراک گذاشته میشود. برای ذخیرهسازی فایلهای پروژه، داکیومنتها، یا لگهای مرکزی — NAS انتخابی عالی است. اما برای دسترسی به دادههای دیتابیس با نیازهای بالا، SAN مناسبتر است. SAN، شبکهای اختصاصی از دیسکها را ایجاد میکند که مستقیماً به سرورها متصل میشوند — معمولاً از طریق Fibre Channel یا iSCSI. این سیستمها، قابلیت اطمینان، امنیت و مدیریت تکرارپذیری (replication) بالایی دارند و در محیطهای تولید سازمانی بسیار رایج هستند. اما برای اکثر توسعهدهندگان فردی یا تیمهای کوچک، NAS کافی است — بهویژه اگر از دستگاههایی مانند Synology DS923+ یا QNAP TS-464 استفاده کنید.
5. Object Storage/ ذخیرهسازی ابری برای مقیاس بینهایت
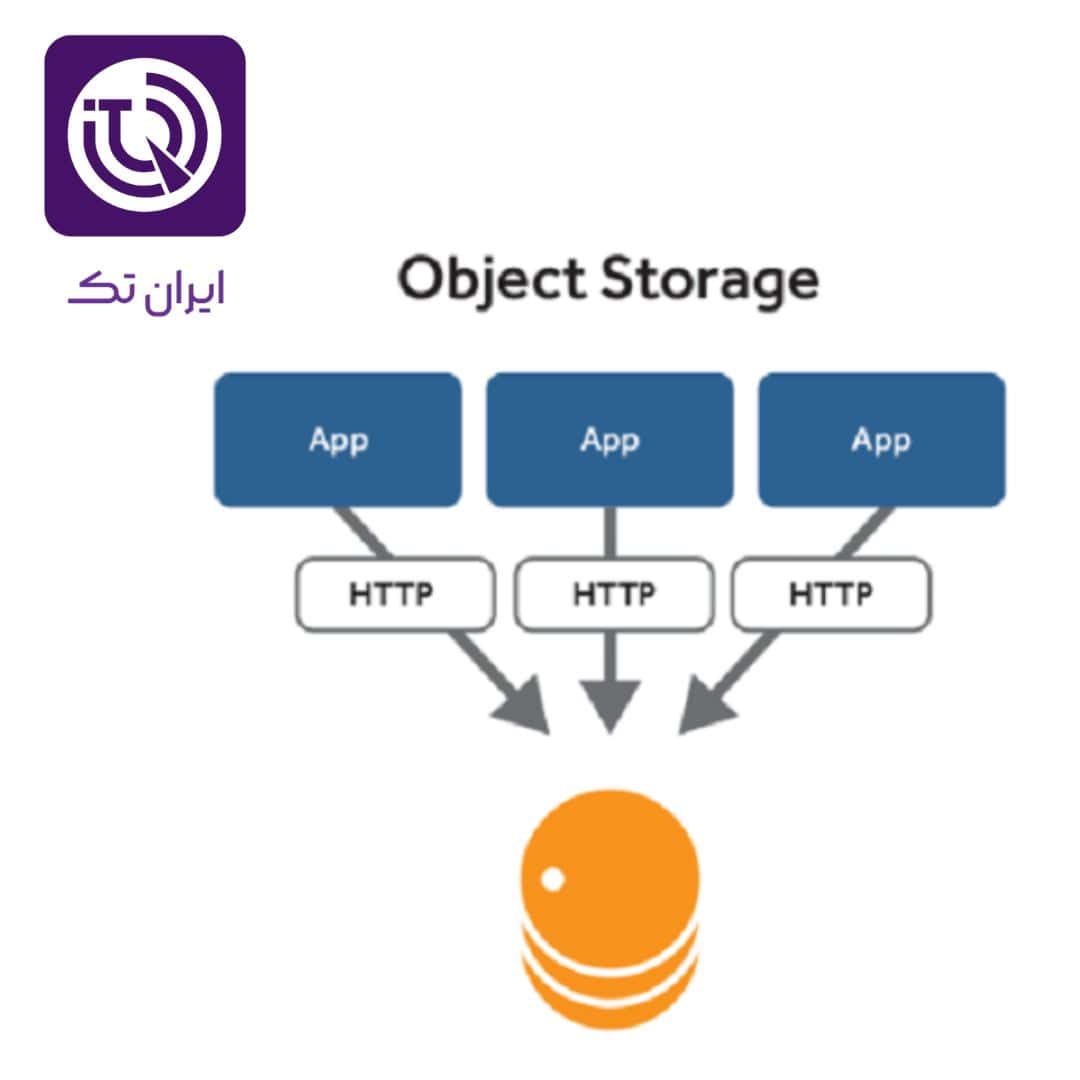
در دنیای امروز، بسیاری از دادهها — مانند تصاویر، ویدیوها، فایلهای آرشیو، یا لگهای اپلیکیشن — نیازی به ساختار دیتابیس رابطهای (relational) ندارند. اینجا است که **Object Storage** وارد میشود. سرویسهایی مانند **Amazon S3**، **Google Cloud Storage**، یا **Backblaze B2**، دادهها را به صورت اشیاء (objects) با متادیتا (metadata) و شناسههای منحصربهفرد ذخیره میکنند. این سیستمها، مقیاسپذیری بینهایت، دسترسی از طریق API، و قابلیت اطمینان بالا (با تکرار در چندین مرکز داده) دارند. برای توسعهدهندگانی که اپلیکیشنهای ابری میسازند — مخصوصاً با معماری Serverless یا Microservices — object storage یکی از ستونهای اصلی است. از طریق SDKهای موجود در Python، Node.js، یا Go، میتوانید به راحتی فایلها را آپلود، دانلود و مدیریت کنید. همچنین، قیمت آنها برای حجم بالا بسیار پایین است: مثلاً Amazon S3 Standard با قیمت حدود ۲.۳ دلار برای هر ترابایت در ماه.
انتخاب تجهیزات ذخیرهسازی بر اساس سناریوی توسعهدهنده
- توسعهدهنده فردی و مبتدی
اگر شما یک توسعهدهنده فردی هستید که از لپتاپ خود برای ساخت اپلیکیشنهای ساده، وبسایتهای استاتیک، یا اپلیکیشنهای موبایل استفاده میکنید — نیاز شما ساده است: یک **NVMe SSD ۵۱۲GB** به همراه یک **HDD ۲TB** برای پشتیبانگیری. این ترکیب، سرعت را برای اجرای کد و تستها فراهم میکند و همزمان فضای ذخیرهسازی برای فایلهای شخصی و پروژههای قدیمی را نیز تضمین میکند. از ابزارهایی مانند **Time Machine** (برای مک) یا **FreeFileSync** برای پشتیبانگیری خودکار استفاده کنید. همچنین، برای پشتیبانگیری ابری، **Backblaze** یا **iCloud** را در نظر بگیرید. این ترکیب، هزینهای حدود ۱۵۰ دلار در سال دارد — و تجربه توسعهدهی را از یک فرآیند تلخ به یک تجربه لذتبخش تبدیل میکند.
- توسعهدهنده تیمی و متوسط
اگر شما بخشی از یک تیم ۵–۱۰ نفره هستید که در یک محیط همگانی کار میکنید — مثلاً یک استارتاپ فناوری — نیاز شما به یک **NAS** با قابلیت RAID 5 یا 6 میرسد. دستگاههایی مانند **Synology DS923+** با ۴ درایو ۸TB، امکان اشتراک فایلهای پروژه، پشتیبانگیری خودکار از دیتابیسهای محلی، و حتی اجرای یک **MinIO** برای ایجاد یک سرویس S3 سازگار را فراهم میکند. همچنین، امکان اتصال به **GitLab Runner** یا **Jenkins** برای اجرای تستهای CI/CD روی سرور محلی — بدون نیاز به ابر — بسیار ارزشمند است. این سیستم، هزینهای حدود ۱,۲۰۰ دلار دارد — اما جایگزینی ارزانتر برای یک سرور ابری با قابلیتهای مشابه ندارد.
- توسعهدهنده سازمانی و پیشرفته
در سازمانهای بزرگ، تجهیزات ذخیرهسازی بخشی از استراتژی IT است. در این سطح، ترکیب **SAN** برای دیتابیسهای حیاتی (مانند Oracle یا SQL Server)، **NAS** برای فایلهای اشتراکی، و **Object Storage** (مانند AWS S3 یا Azure Blob Storage) برای دادههای غیرساختاری — استاندارد است. همچنین، استفاده از **Storage Class Memory (SCM)** مانند Intel Optane برای کشهای حافظه بسیار پیشرفته — که بین RAM و SSD قرار دارد — در محیطهایی با نیاز به تأخیر کمتر از ۱۰ میکروثانیه رایج است. این تجهیزات، هزینههای بالایی دارند — اما برای شرکتهایی که هر ثانیه تأخیر، میلیونها دلار ضرر میآورد — ارزش آن را دارد. همچنین، استفاده از **Ceph** یا **GlusterFS** برای ایجاد یک سیستم ذخیرهسازی مقیاسپذیر و باز (open-source) — بدون وابستگی به ابرهای خارجی — در بسیاری از سازمانهای اروپایی و آمریکایی رایج است.
تجهیزات ذخیرهسازی ابری/ راه حلهای مدرن برای توسعهدهندگان

🔧 Amazon S3: استاندارد صنعتی
Amazon Simple Storage Service (S3) — با بیش از ۱۰ سال سابقه — هنوز هم به عنوان استاندارد صنعتی برای object storage شناخته میشود. امکاناتی مانند **versioning**، **lifecycle policies**، **cross-region replication**، و **server-side encryption** — همه از جمله ویژگیهایی هستند که توسعهدهندگان امروزی بدون آن نمیتوانند کار کنند. از طریق AWS CLI یا SDKهای موجود در هر زبان برنامهنویسی، میتوانید به راحتی فایلهای خود را آپلود کنید. همچنین، ادغام با **AWS Lambda**، **CloudFront**، و **Glacier** برای آرشیو کمهزینه — این سرویس را به یک اکوسیستم کامل تبدیل کرده است. برای توسعهدهندگانی که از **Serverless** استفاده میکنند — S3 نه تنها یک گزینه، بلکه یک الزام است.
🔧 Google Cloud Storage (GCS)
اگر به دنبال عملکرد بالاتر در خواندن دادههای کوچک و پشتیبانی از **multi-regional** و **nearline** storage هستید — GCS یک گزینه بسیار قوی است. بهویژه در محیطهایی که از **BigQuery** یا **TensorFlow** استفاده میکنید، ادغام با GCS بسیار روان است. همچنین، قابلیت **Uniform Bucket-Level Access** و **Object Lifecycle Management** — به صورت پیشرفته و بدون نیاز به ACLهای پیچیده — از مزایای منحصر به فرد آن است.
🔧 Microsoft Azure Blob Storage
برای تیمهایی که در اکوسیستم Microsoft — مانند .NET، Azure Functions، یا SQL Server — کار میکنند، Blob Storage انتخابی طبیعی است. امکان استفاده از **Azure Data Box** برای انتقال حجمهای عظیم داده به ابر — و همچنین ادغام با **Azure Synapse Analytics** — آن را برای سازمانهای بزرگ بسیار جذاب کرده است.
🔧 Backblaze B2: جایگزین مقرونبهصرفه
اگر هزینههای AWS یا Azure برای شما بالا است — Backblaze B2 یک جایگزین بسیار هوشمندانه است. با قیمت ۰٫۰۰۵ دلار برای هر گیگابایت در ماه — و بدون هزینه برای درخواستهای خواندن — این سرویس، برای استارتاپها و توسعهدهندگان فردی بسیار مناسب است. همچنین، از پروتکل S3 پشتیبانی میکند — بنابراین میتوانید بدون تغییر کد، از S3 به B2 منتقل شوید.
🔧 Wasabi: بدون هزینههای ناخواسته
Wasabi یکی دیگر از گزینههای جذاب است که هیچ هزینهای برای درخواستهای خواندن یا تحویل داده (egress) ندارد. این ویژگی، برای اپلیکیشنهایی که فایلهای زیادی را به کاربران ارسال میکنند — مانند سرویسهای استوریج تصویر — بسیار مهم است. همچنین، قیمت آن حدود ۶۰٪ کمتر از AWS S3 است — و بدون محدودیتهای پیچیدهی تعرفههای ابری.
تکنولوژیهای نوظهور/ SCM- Ceph و File Systemهای مدرن
Storage Class Memory /SCM و Intel Optane
این تکنولوژیها، مرز بین RAM و SSD را از بین میبرند. Intel Optane (اکنون تحت مالکیت Micron) از فناوری 3D XPoint استفاده میکند و تأخیری کمتر از ۱۰ میکروثانیه دارد — در حالی که ظرفیت آن تا ۵۱۲GB میرسد. این تجهیزات، در سرورهای دیتابیسی با نیاز به کش بسیار سریع — مانند Redis با حجم بالا یا PostgreSQL با کش بزرگ — بسیار مؤثر هستند. اگر شما در یک محیط با تأخیر بحرانی کار میکنید — مانند تریدینگ الکترونیکی یا سیستمهای پزشکی در زمان واقعی — این تکنولوژیها، نه یک گزینه، بلکه یک ضرورت هستند.
Ceph/ ذخیرهسازی باز و مقیاسپذیر

Ceph یک سیستم ذخیرهسازی open-source است که میتواند به صورت **object**، **block**، و **file** در یک سیستم واحد پشتیبانی کند. برای توسعهدهندگانی که میخواهند از ابرهای خارجی مستقل باشند — Ceph یک راه حل عالی است. با استفاده از **Rook** و **Kubernetes**، میتوانید یک سیستم ذخیرهسازی مقیاسپذیر و خودکار را در کلاستر خود ایجاد کنید. این سیستم، از **erasure coding** و **replication** پشتیبانی میکند و در محیطهایی که امنیت و کنترل کامل بر دادهها مهم است — مانند دولتها، بانکها و شرکتهای فینتک — بسیار رایج است.
File Systemهای مدرن/ ZFS و Btrfs

در سیستمهای لینوکس، فایلسیستمهای مدرن مانند **ZFS** و **Btrfs** — که از امکاناتی مانند **snapshots**، **compression**، **checksumming**، و **self-healing** پشتیبانی میکنند — در حال جایگزینی ext4 و XFS میشوند. ZFS بهویژه برای سرورهای ذخیرهسازی پیشرفته — مانند NASهای سازمانی — بسیار مناسب است. این فایلسیستمها، از خطاهای دادهای (bit rot) جلوگیری میکنند و امکان بازیابی لحظهای از دادهها را فراهم میکنند — یک ویژگی حیاتی برای توسعهدهندگانی که به دنبال امنیت دادههای خود هستند.
راهکارهایی جهت بهینهسازی تجهیزات ذخیرهسازی داده
- استراتژی لایهبندی ذخیرهسازی (Tiered Storage)
یکی از بهترین راهکارهای عملی برای توسعهدهندگان، استفاده از **لایهبندی ذخیرهسازی** است. این یعنی:
- **لایه ۱ (Hot)**: NVMe SSD — برای دیتابیسهای فعال، کشها و فایلهای پروژه در حال استفاده
- **لایه ۲ (Warm)**: SATA SSD — برای دادههای کمتر فعال، لگهای روزانه، و فایلهای تست
- **لایه ۳ (Cold)**: HDD — برای آرشیو، فایلهای قدیمی، و پشتیبانهای ماهانه
- **لایه ۴ (Archive)**: Object Storage (S3 Glacier یا Backblaze Coldline) — برای دادههایی که چند سال بعد نیاز به بازیابی دارند
این استراتژی، نه تنها هزینه را کاهش میدهد، بلکه عملکرد را بهینه میکند. ابزارهایی مانند **Rclone** یا **AWS DataSync** میتوانند به صورت خودکار دادهها را بین لایهها منتقل کنند.
- پشتیبانگیری هوشمند: ۳-۲-۱ Rule
هر توسعهدهندهای باید از قاعده **۳-۲-۱** پیروی کند:
- **۳ نسخه** از دادهها داشته باشید
- **۲ نوع** تجهیزات مختلف (مثلاً SSD + NAS)
- **۱ نسخه** در خارج از محل (مثلاً ابر یا دیسک خارجی در محل دیگر)
این قاعده، شما را از از دست دادن دادهها به دلیل سیل، سرقت، یا خرابی سختافزار محافظت میکند. ابزارهایی مانند **BorgBackup**، **Restic**، یا **Duplicati** — که از رمزنگاری و تکرار حذف (deduplication) پشتیبانی میکنند — بسیار مناسب هستند.
- استفاده از Docker و Volume Management
در محیطهای توسعهدهنده مدرن، Docker یک استاندارد است. اما بسیاری از توسعهدهندگان، دادههای دیتابیس را درون کانتینرها ذخیره میکنند — که در صورت حذف کانتینر، دادهها از بین میروند. راه حل: استفاده از **Docker Volumes** یا **Bind Mounts** به یک دایرکتوری خارجی (مثلاً `/data/postgres` روی یک NVMe SSD). همچنین، از **docker-compose.yml** استفاده کنید و حجمها را به صورت واضح تعریف کنید:
```yaml
volumes:
- ./data/postgres:/var/lib/postgresql/data
```
این کار، امکان بازیابی، انتقال، و اجرای تستهای تکرارپذیر را فراهم میکند.
نکات امنیتی و مدیریتی برای ذخیرهسازی داده
📌 رمزنگاری در سطح سختافزار و نرمافزار
اگر دادههای شما حساس هستند — مانند اطلاعات کاربران، رمزهای عبور، یا دادههای مالی — باید از **encryption at rest** و **encryption in transit** استفاده کنید. سرویسهای ابری مانند AWS و Google Cloud، این امکان را به صورت پیشفرض فراهم میکنند. اما در سیستمهای محلی — باید از **LUKS** (Linux Unified Key Setup) برای رمزنگاری دیسک یا **Veracrypt** برای ایجاد حجمهای رمزنگاری شده استفاده کنید. همچنین، از **Vault** از HashiCorp برای مدیریت کلیدهای رمزنگاری و دسترسیهای مبتنی بر نقش (RBAC) استفاده کنید.
📌 نظارت و گزارشدهی: چه چیزی در حال انجام است؟
استفاده از ابزارهایی مانند **Prometheus** با **node_exporter** برای نظارت بر فضای دیسک، سرعت خواندن/نوشتن، و دما — میتواند از خرابیهای پیشرو جلوگیری کند. همچنین، از **Netdata** برای نمایش زنده عملکرد دیسک استفاده کنید. یک سرور با ۹۸٪ فضای پر، بدون هشدار — یک کاراگاه است. تیمهای فنی موفق، این نظارت را به عنوان بخشی از CI/CD خود در نظر میگیرند.
📌 مدیریت چرخه عمر داده (Data Lifecycle Management)
دادهها زنده نیستند — آنها میمیرند. بسیاری از تیمها، دادههای تستی، لگهای قدیمی، و فایلهای موقت را به صورت نامحدود نگه میدارند. این کار، هزینه را افزایش میدهد و عملکرد را کاهش میدهد. استفاده از **lifecycle policies** در S3، یا اسکریپتهای cron در لینوکس برای حذف فایلهای قدیمی (مثلاً فایلهایی که بیش از ۳۰ روز قدیمیاند) — یک عادت حرفهای است. این کار، نه تنها فضا را نجات میدهد، بلکه امنیت را نیز افزایش میدهد.
همچنین مقاله های زیر را مطالعه نمایید:
کلام آخر/ تجهیزات ذخیرهسازی داده- نه گرانترین بلکه هوشمندانه
انتخاب تجهیزات ذخیرهسازی داده، نه یک تصمیم فنی ساده است، بلکه یک تصمیم استراتژیک است که بر تمامی جنبههای توسعه نرمافزار تأثیر میگذارد. یک توسعهدهنده فردی که از NVMe SSD و Backblaze B2 استفاده میکند — نه تنها با سرعت بیشتری کار میکند، بلکه از خطاها، تأخیرها و استرسهای ناشی از از دست دادن دادهها نیز جلوگیری میکند. یک تیم متوسط که از NAS با RAID 6 و پشتیبانگیری خودکار استفاده میکند — نه تنها از دادههای خود محافظت میکند، بلکه اعتماد کاربران و مشتریان خود را نیز تقویت میکند. و یک سازمان بزرگ که از ترکیب SAN، Ceph و S3 با لایهبندی هوشمند استفاده میکند — نه تنها مقیاسپذیری را دارد، بلکه از دستیابی به اهداف تجاری خود نیز اطمینان دارد. انتخاب تجهیزات ذخیرهسازی، نه باید بر اساس برند معروف یا تبلیغات باشد، بلکه باید بر اساس نیاز واقعی، مقیاس فعلی، و رشد آینده شما باشد. ایران تک با این مقاله، شما را نه تنها با ابزارها آشنا کرد، بلکه به شما آموخت که چگونه با آنها فکر کنید.
سوالات متداول
آیا HDD هنوز برای توسعهدهندگان مناسب است؟
فقط برای آرشیو یا پشتیبانگیری غیرفعال. برای دیتابیس یا اجرای کد، نه.
بهترین ترکیب برای توسعهدهنده فردی چیست؟
NVMe SSD ۱TB + Backblaze B2 + رمزگذاری LUKS.
آیا میتوانم از SSD ابری به جای SSD فیزیکی استفاده کنم؟
بله — اما برای توسعه محلی، SSD فیزیکی همیشه سریعتر و مقرونبهصرفهتر است.

